Real People. Real Insights. AI-Enhanced Intelligence
We collect authentic data from real people across emerging markets and use AI to deliver insights faster and more accurately than ever before. We believe human voices matter - and AI helps us hear them more clearly.
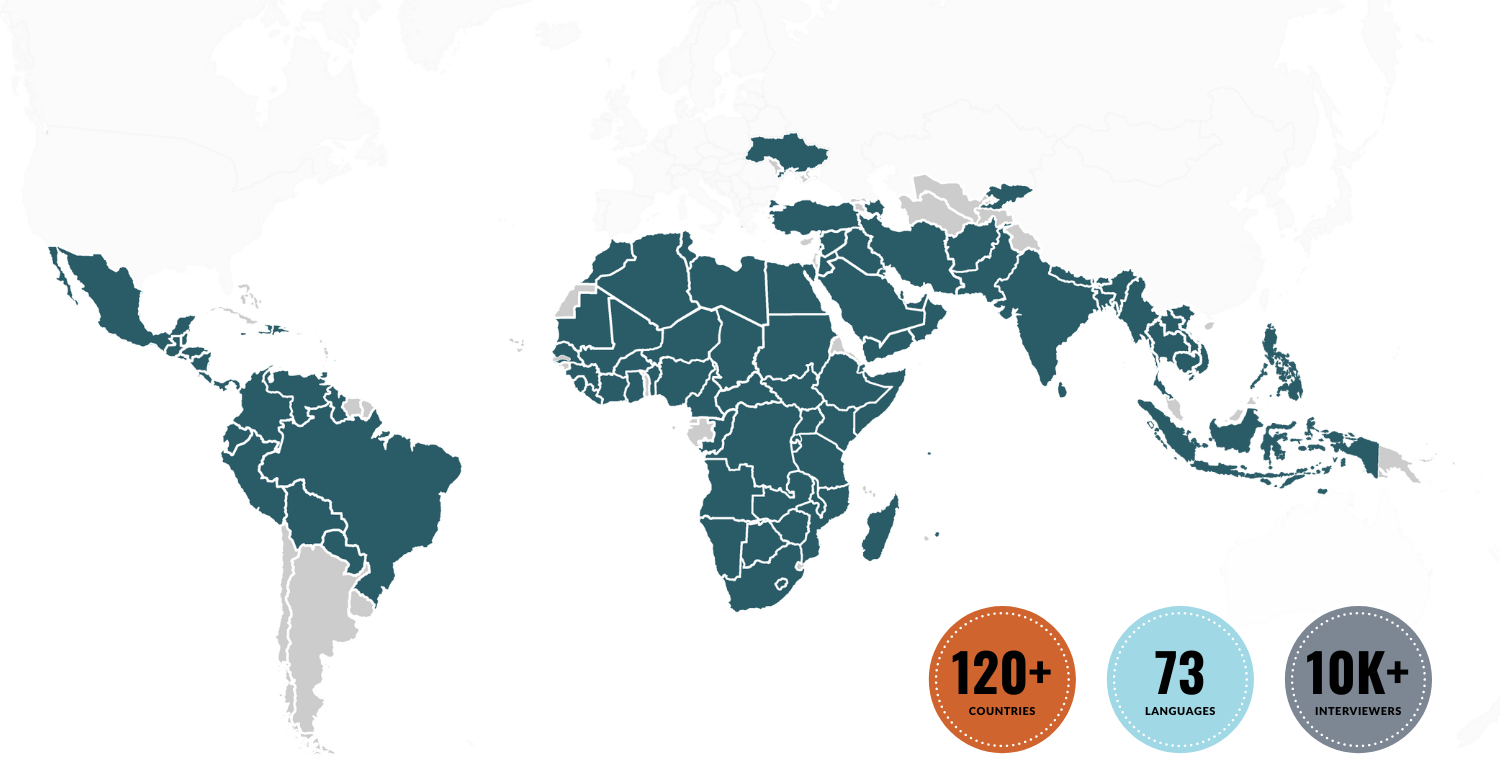
Global Coverage
GeoPoll offers full-service research solutions in 120+ countries worldwide. Every year, we conduct over 5 million surveys across multiple mobile modes, tapping into a vast network of 10,000+ trained interviewers in 65 call centers and partnerships with mobile network operators. Our reach extends to a profiled panel of 5 million respondents, with direct access to 300+ million people across Africa, Asia, and Latin America to ensure diverse representation in every study.
Who We Work With
GeoPoll delivers critical insights to everyone from international development organizations and global brands to local NGOs and retailers.



“GeoPoll did an amazing job for us with the SMS based survey, the process of data collection was fast with feedback being given at every turn. ”
ActionAid Zimbabwe
“GeoPoll was very helpful in supporting delivery of IMSARs objectives, and excelled by providing quality, reliable and verifiable data. They executed the survey to perfection, kept IMSAR informed about every step of the study and provided timely guidance to IMSAR on survey and technological aspects. Their expertise especially in use of CATI for data collection is unmatched, which makes GeoPoll highly reliable.”
Palladium Rwanda
“In 2020, DAI engaged GeoPoll to carry out two time-sensitive surveys of agrodealers in Nigeria and Ethiopia. GeoPoll provided almost daily updates on progress, regularly consulted on adjustments needed to conduct the survey, and brought surveys to a smooth conclusion, enabling us to provide valuable insights to our client.”
DAI
Our Value
Our technology, expert team, and network of vetted partners and call centers enable us to collect and process high-quality, high-frequency data at scale faster than anyone else.

Quality Centric
Quality is paramount at GeoPoll. We blend intelligent software with expert oversight to guarantee accurate, unbiased data that is scientifically valid and trustworthy for your research needs. Our platform automatically checks responses for anomalies and flags issues in real time. For phone-based surveys, we go a step further: AI agents review call transcripts to confirm enumerators are following training protocols, asking questions correctly, maintaining tone, and staying on script. Long pauses or inconsistencies are flagged for human follow-up. These automated checks, paired with a human review of data and audio, mean that every survey undergoes rigorous validation, so you can trust the results.

Local Context
GeoPoll operates at the intersection of local context and global reach. We have a truly global presence – with main operations based in Kenya, headquarters in the US and offices in Africa, Asia and Latin America to ensure that every project benefits from in-depth regional knowledge. Supported by a vetted network of 10,000+ trained interviewers in 65+ countries, we design research that resonates culturally while maintaining international standards. This local expertise is augmented by our proprietary AI tools (such as natural language processing for local dialects) to capture nuances in each region at scale.

Speed at Scale
It’s a fast-paced world, and timely data is key. GeoPoll delivers unmatched speed in turning around high-volume research projects. Thanks to our AI-augmented processes and time-tested methodologies, we can deploy surveys and analyze results faster than ever. Data is available in real time through our client portal and data API, and final reports available right after the data collection is complete. We have fielded rapid-turnaround surveys within hours of breaking events or emergencies, putting critical data at our clients’ fingertips when it matters most. That means you get reliable data at lightning speed to drive agile decision-making.
Transparent Intelligence
We start every research with the end in mind – practical, usable and data-first reporting so you can reliably make decisions. We go above and beyond by granting partners access to raw data files, interactive dashboards, and live data portals, and our data platforms are designed with user-friendly clarity, enabling you to explore and verify findings directly. We have incorporated advanced AI analyses for faster insights without compromising the authentic human perspective that makes data truly valuable, and remain committed to making the process interpretable and clear.
Innovative Technology Platform
At the heart of GeoPoll is an innovative research platform that integrates multiple data collection modes with AI-driven analytics. This robust platform has processed over 53 million interviews since 2014, proving its reliability and scale. We support a wide range of methodologies – from face-to-face interviews and live phone calls to SMS, mobile web links, and app-based surveys – all within one centralized system. Our in-house software development team continually enhances the platform and can customize it to meet specific project needs. We combine human-centered design with machine efficiency to ensure flexibility, data security, and adaptability. The result is a powerful, AI-enabled research engine that delivers high-quality data from any environment straight to your analysis dashboard.

Blogs & Reports
The Seed Marketing Report: How Farmers in Kenya and Uganda Choose, Use, and Trust Maize and Bean Seeds
GeoPoll and Resourced are pleased to release a new multi-year study that sheds light on how farmers in Kenya and Uganda discover, […]
Africa’s Digital Future Unfolds at MWC Kigali: Reflections from GeoPoll
I had the opportunity to attend the GSMA Mobile World Congress (MWC) Africa 2025 in Kigali, Rwanda, one of the continent’s most […]
Kenya’s Financial Landscape Report
Kenya’s financial landscape stands as one of the most dynamic in Africa, driven by rapid digitization, high mobile money adoption, and continued […]
GeoPoll Launches Senselytic to Bring AI-Powered Qualitative Insight to Quantitative Surveys
GeoPoll is pleased to announce the launch of GeoPoll Senselytic, a new AI-powered capability designed to extend traditional quantitative surveys with automated […]
Tanzania’s Financial Landscape: Mobile Money Dominates, But Challenges Remain
The Tanzanian financial sector is evolving rapidly, mirroring broader regional trends highlighted in the GeoPoll Financial Landscape in Africa 2025 report. With […]
GeoPoll Report: CHAN 2024 Study
The African Nations Championship (CHAN) is a biennial football tournament organized by the Confederation of African Football (CAF), featuring national teams composed […]
From our CEO: How GeoPoll is Using AI to Strengthen Real-World Research
Real People. Real Insights. AI-Enhanced Intelligence For over a decade, GeoPoll has supported development agencies, governments, researchers, media houses, and commercial clients […]