GeoPoll AI Data Streams™
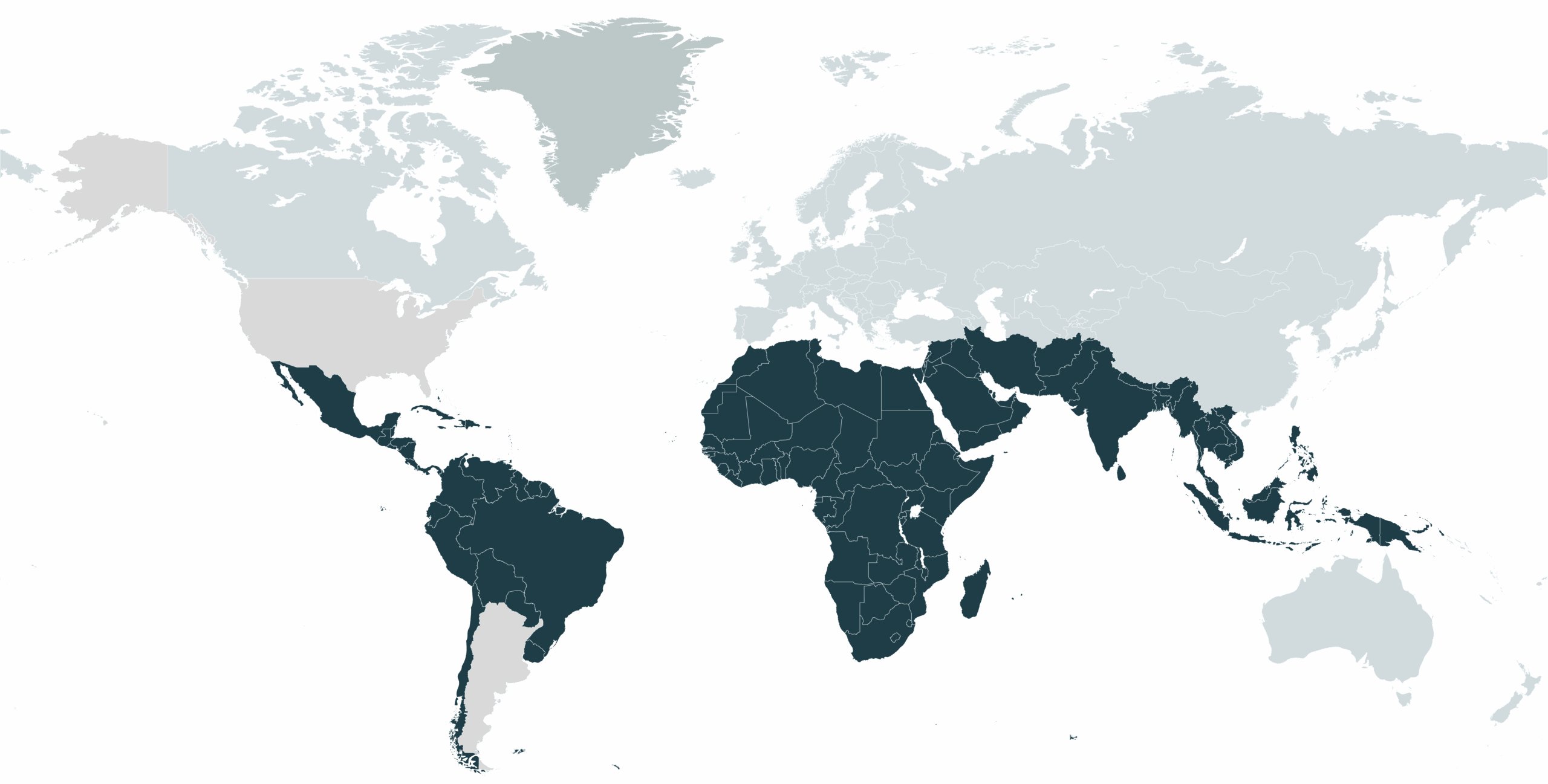
Over 500,000 hours of diverse, representative, and high-quality voice recordings from 1 million+ individuals covering over 100 languages and dialects across Africa, Asia, and Latin America for your LLM training.
Models trained on GeoPoll AI Data Streams achieve <3% transcription WER even in low-resource, noisy, or dialect-rich settings.

Our Value
We start with the world’s largest database of audio recordings from Africa, Asia, and Latin America. Through transcription, diarization, and metadata enrichment, we develop high-quality labeled datasets ready for fine-tuning LLMs, training ASR systems, and advancing generative voice technology. In short, we deliver gold-standard, fit-for-purpose data from underrepresented languages and accents, in any format clients require.

Human-Centric
Our datasets capture real conversations from real people, ensuring the authenticity and contextual depth necessary for reliable model training.

Volume and Coverage
GeoPoll’s reach spans 1M+ unique speakers and 100+ languages/dialects, producing significantly more low-resource language data than typical open or scripted datasets.

Conversational Context
Structured scripts provide consistency for benchmarking while retaining the natural variation, code-switching, and unpredictability of human speech.

Precise Transcriptions
All audio is human-transcribed, time-aligned, and enriched with metadata for speaker separation, demographics, and linguistic variation.
Access over 500,000 Hours of AI-Ready recordings from Africa, Asia and Latam
Use Cases & Applications
Commercial Businesses & Brands
- Intelligent virtual assistants and conversational AI for customer service
- Personalized product recommendations and targeted marketing
- Sentiment analysis and voice-of-customer analytics
- Forecasting models for sales, demand, and supply chain optimization
- Language translation and content localization
Social/Humanitarian Initiatives:
- AI-powered education and literacy tools for underserved communities
- Health information chatbots for public awareness and preventive care
- Early-warning systems and response coordination for crisis situations
- Financial inclusion programs with personalized advisory and lending
- Surveys and feedback analysis to identify grassroots needs
Tech Companies:
- General-purpose language models for NLP tasks and applications
- Customized, domain-specific AI solutions for verticals like healthcare, finance, food security, etc.
- Multilingual AI assistants for global product/service experiences
- Research in areas like multimodal learning, transfer learning, few-shot learning
Academic Research:
- Natural language processing and generation studies
- Sociolinguistic research and language preservation efforts
- Public policy analysis and social science explorations
- Biomedical and scientific research publications
- Dataset creation and benchmarking for AI model evaluation
What's Typically Included
We deliver not just recordings, but full data packages enriched with transcriptions, speaker metadata, and linguistic labels for seamless AI training.
-
Audio: Conversational recordings with diarization and speaker separation
-
Transcripts: Human-written, time-aligned, with translations where available
-
Metadata: Speaker demographics, region, language/dialect tagging, environment/context notes
-
Annotations: Entities, sentiment, intent, and thematic labels
Let’s discuss your data needs
Fill this form for more details into the languages, countries, and themes we cover, and get sample data